
Transcribing audio to text used to take hours of manual work. Today, AI transcription tools can convert speech into accurate text in minutes.
Whether you’re working with lectures, meetings, interviews, podcasts, or videos, modern AI tools make transcription fast, scalable, and affordable.
In this guide, you’ll learn:
Tips to improve transcription accuracy
What audio transcription is
The difference between manual and AI transcription
A step-by-step workflow for automatic transcription
The best AI transcription tools
Understanding Audio Transcription
Audio transcription is the process of converting spoken words from an audio recording into written text. This seemingly simple task can have profound benefits:
- Improved Accessibility: Transcripts make your content available to those who are deaf or hard of hearing, as well as to those who prefer reading over listening.
- Enhanced SEO: Search engines can’t crawl audio content, but they can index text. Transcripts can significantly boost your content’s visibility online.
- Better Content Organization: Written transcripts are easier to search, reference, and organize than audio files.
Most Popular Methods for Audio-to-Text Transcription
There are two primary methods for transcribing audio to text:
1. Manual Transcription
Manual transcription involves listening to the audio and typing out the content by hand. While this method can be highly accurate, it’s also time-consuming and labor-intensive.
Pros:
- High accuracy, especially for complex or technical content
- Ability to capture nuances and context
Cons:
- Very time-consuming
- Prone to human error, especially for long recordings
Manual transcription is best suited for short, critical pieces of audio where absolute accuracy is paramount.
2. Automated Transcription Tools
AI-powered transcription tools have revolutionized the process, offering speed and convenience that manual methods can’t match. VOMO AI stands out as a leading option in this field.
Manual vs. AI Transcription: Which One Should You Choose?
Different transcription methods serve different needs. Manual transcription is performed by professional transcribers who type out every word verbatim. It is mainly used in fields that demand extremely high accuracy, such as legal, medical, or academic contexts. Accuracy can often reach 100%, but this comes with a very high cost and longer turnaround times.
On the other hand, AI-powered automatic transcription tools are designed for users who need fast, large-volume transcription. They provide excellent accuracy for most purposes without requiring every word to be perfect, and their cost is only a fraction of manual transcription.
Comparison of Manual and AI Transcription
| Feature | Manual Transcription | AI Transcription |
|---|---|---|
| Accuracy | Up to 100% | High (typically 95–99%) |
| Speed | Slow – hours per hour of audio | Fast – minutes per hour of audio |
| Cost | Very high | Low (a fraction of manual cost) |
| Best Use Cases | Legal, medical, academic transcription | Meetings, podcasts, lectures, webinars, bulk transcription |
| Scalability | Limited | Easily handles large volumes |
| Error Handling | Human-reviewed, highly reliable | AI-assisted, may require minor editing |
How to Transcribe Audio Automatically Online: A Step-by-Step Guide
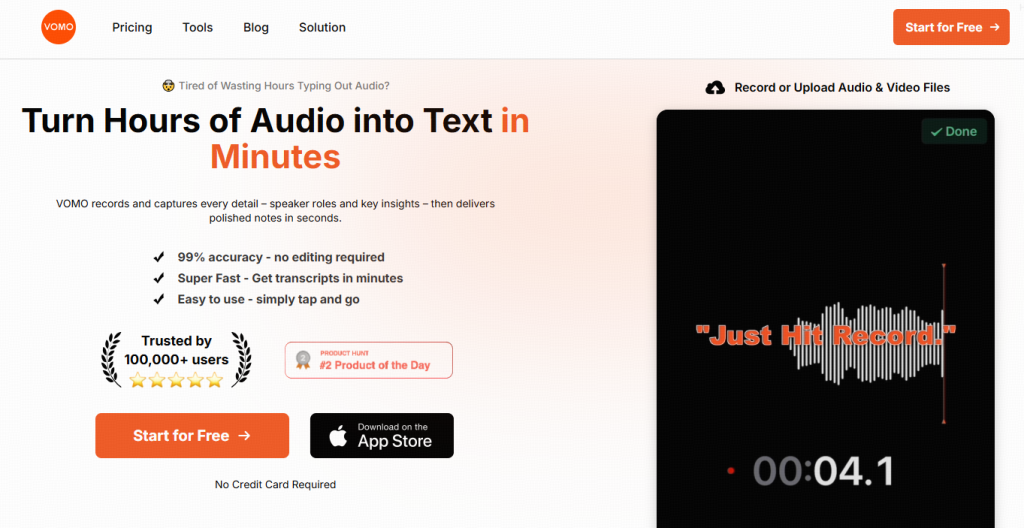
Step 1: Record or Upload Your Audio
You can start by either recording audio or uploading an existing file.
Most tools support formats like:
- MP3
- WAV
- M4A
- MP4
- MOV
For example, VOMO AI allows you to:
- Record audio directly inside the app
- Upload existing recordings
- Import video files for transcription
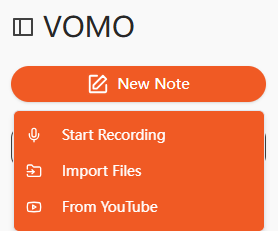
Step 2: Start the AI Transcription
Once the audio file is uploaded, the AI system automatically:
- Analyzes the audio waveform
- Detects words and speech patterns
- Identifies different speakers
- Adds punctuation and formatting
The transcription process usually takes only a few minutes.

Step 3: Review and Edit the Transcript
After transcription is complete, you can review and edit the text.
Most AI tools provide:
- Timestamped transcripts
- Speaker labeling
- Text editing tools
- Copy / export options
A quick review ensures the transcript is 100% accurate and readable.

Step 4: Enhance the Transcript
Advanced transcription tools offer additional features such as:
- AI meeting summaries
- Key point extraction
- Keyword search
- Transcript-based editing
These features help turn transcripts into actionable insights.

Transcribing Audio and Video on Your Phone
Mobile transcription is convenient for on-the-go recording:
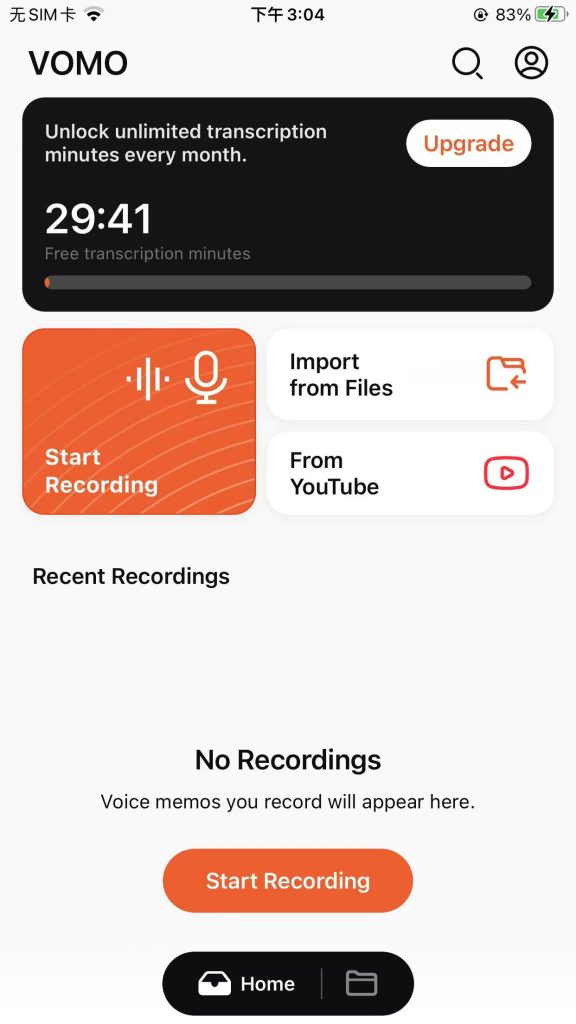
- Open VOMO AI app
- Start a new recording
- AI automatically transcribes your audio in real time
- Edit, export, or share directly from your device
This is ideal for lectures, meetings, podcasts, or interviews when you’re away from a computer.
How to Transcribe Videos from Different Platforms
Transcribing videos from social media or online platforms like YouTube, Instagram, Facebook, Twitter, and others has become increasingly easy thanks to modern AI transcription tools. These tools allow you to convert spoken content from any platform into text quickly and accurately. Here’s how you can handle different platforms:
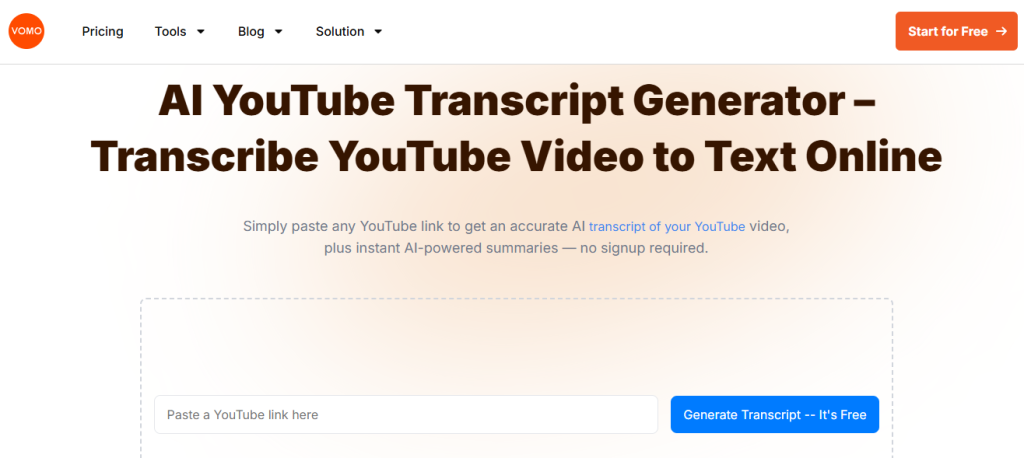
YouTube
Most AI transcription tools let you upload YouTube videos directly via URL or by downloading the video first. The tool will extract the audio and generate a text transcript. Many tools also allow you to automatically add captions to your video.
You can use VOMO’s YouTube transcription tool below.
For Instagram videos or Reels, you can download the video using a compatible downloader, then upload the file to your AI transcription tool. Some tools can even process stories or live recordings, giving you a transcript ready for captions, social media repurposing, or content analysis.
You can use the following VOMO Instagram Reels transcription tool.
Facebook videos, including live streams and uploaded clips, can be transcribed in a similar way. After downloading the video, AI transcription software can generate a transcript, label different speakers, and even summarize key points for easier reference.
Twitter / X
Twitter videos, whether in tweets or Spaces recordings, can be downloaded and transcribed using the same workflow. AI transcription tools handle different accents and audio quality, ensuring you get an accurate text version of your content.
Best Transcription Tools Compared
Generally speaking, most AI transcription tools use similar underlying models. As a result, their transcription performance is quite good, except for tools like Otter.ai that rely on older models and may be less accurate. VOMO AI, however, integrates multiple AI transcription models, delivering even better results.
| Tool | Type | Accuracy | Languages | Features | Free Option |
|---|---|---|---|---|---|
| VOMO AI | AI-powered | Up to 99% | 57 language | Batch transcription, meeting summaries, key point extraction, AI chat, cross-device sync | 30 min/month |
| Riverside | AI-powered | Up to 99% | 100+ | Video + audio, speaker labels, text-based editing, captions, filler word removal | Limited free plan |
| Otter.ai | AI-powered | High | English | Real-time transcription, speaker labeling, meeting summaries, AI chat, collaboration | Free tier available |
| Rev Voice Recorder | AI/Human | Up to 90% AI, 99% Human | English | Live transcription, Zoom/Teams integration, in-app collaboration | Free AI recording; human transcription paid |
| Google Recorder / Live Transcribe | On-device AI | Moderate | Multiple | Real-time transcription, offline support | Free |
| Microsoft Word Transcribe | AI-powered | High | English | Upload audio, inline editing, timestamps | Included with Office subscription |
How Does Audio-to-Text Transcription Work?
AI transcription software converts speech into text using acoustic and language models.
- Acoustic model: Breaks audio into small sound patterns and predicts words
- Language model: Evaluates sequences for context and accuracy
- Some tools also identify speakers, add punctuation, and format text automatically
The process mimics human transcription but happens within seconds or minutes.
Advanced Features of VOMO AI
VOMO AI offers several features that set it apart:
- AI Chat Interaction: Engage with your transcript through an AI chat interface, asking questions or seeking clarification on specific points.
- Voice Memo Organization: Easily categorize and search through your transcribed voice memos.
- Cross-Device Syncing: Access your transcripts and recordings from any device with the Vomo app.
Tips for Optimal Audio-to-Text Transcription
- Record in a quiet environment
- Speak clearly and at a moderate pace
- Use a high-quality microphone positioned correctly
- Review and edit transcripts for accuracy and readability
Benefits of Transcribing Your Audio
Make Content Accessible to Everyone
Transcripts help make your audio and video content accessible to a wider audience, including people who are deaf or hard of hearing. They also allow viewers who prefer reading over listening to engage with your content more easily. Adding captions or subtitles from transcripts further enhances inclusivity.
Boost Your SEO and Online Visibility
Search engines cannot “listen” to audio, but they can read text. By providing transcripts for podcasts, webinars, or videos, you make your content indexable, improving discoverability on Google and other search platforms. This can significantly increase your reach and engagement.
Repurpose Content Efficiently
A transcript turns spoken content into a versatile text resource. You can quickly create blog posts, social media updates, summaries, or newsletters without starting from scratch, saving time and effort while maximizing content value.
Simplify Editing with Text-Based Tools
Many AI transcription tools allow you to edit your audio or video directly via the transcript. This text-based editing makes it easy to remove filler words, trim segments, or rearrange sections without re-recording.
Maintain Organized and Searchable Records
Transcripts provide a convenient, searchable record of meetings, interviews, lectures, or webinars. They reduce storage needs compared to raw audio and make it easier to reference or share important details later.
Accuracy and Limitations of AI Transcription
AI transcription tools are fast and convenient, but their accuracy can vary depending on several factors. The quality of your audio recording is key—clear speech with minimal background noise ensures the best results. Accents, multiple speakers, and overlapping conversations can also affect the accuracy, sometimes leading to errors or misheard words.
While AI transcription is much faster than manual or professional human transcription, it may not always perfectly capture every word, especially in complex or technical discussions. On the other hand, manual transcription gives you more control, and professional human services offer the highest precision, handling context, tone, and industry-specific terminology accurately.
Key Points to Consider:
- Audio quality matters: Background noise or low-volume speech can reduce accuracy.
- Multiple speakers: AI tools may confuse overlapping voices or fail to label speakers correctly.
- Accents and dialects: Heavy accents can lead to misinterpretation.
- Complex terminology: Technical or specialized language may require manual review.
In short, AI transcription is excellent for speed and efficiency, but for critical content—such as legal, medical, or highly technical recordings—human review or professional services may still be necessary to ensure perfect accuracy.
Comparing VOMO AI to Other Transcription Services
While there are several transcription services available, VOMO AI stands out for its:
- Advanced AI capabilities, offering high accuracy and additional features like summarization and key point extraction.
- User-friendly interface, making it easy for anyone to use, regardless of technical expertise.
- Seamless integration of recording, transcription, and organization features in one app.
As noted by Happy Scribe, many services offer either human transcription for high accuracy or automated transcription for speed. VOMO AI bridges this gap, providing AI-powered transcription that approaches human-level accuracy while maintaining the speed and convenience of automation.
Get Started with the Best AI Transcription Tool
Don’t let valuable information remain locked in audio format. Download the VOMO app from the App Store today and start transcribing your voice memos with ease. Experience the power of AI-assisted transcription and unlock new levels of productivity and content organization.
FAQ
Can Google transcribe audio to text?
Yes, via Google Docs, Google Meet, and Google Live Transcribe.
Can ChatGPT transcribe audio?
Yes, using Whisper API, but it doesn’t label speakers or format the transcript.
Are there free AI transcription tools?
Yes, Google Recorder, Rev Voice Recorder, and VOMO AI (30 min/month free) are great options.
