
Genaue Transkription stützt sich stark auf die Qualität Ihres Tons. Selbst die besten KI-gestützte Transkriptionstools können Probleme mit Hintergrundgeräuschen, geringer Lautstärke oder sich überlagernder Sprache haben.
Wenn Ihr Ton unordentlich ist, wird auch Ihre Abschrift unordentlich sein, was zu einem zusätzlichen Zeitaufwand für die Bearbeitung und Korrektur von Fehlern führt.
Deshalb ist Reinigung Ihres Audios vor der Transkription ist eine der klügsten Entscheidungen, die Sie treffen können.
In diesem Leitfaden führen wir Sie durch praktische Schritte, um verrauschte Audiodaten zu bereinigen und die besten Ergebnisse mit jeder Transkriptionsanwendung zu erzielen.
🎧 1. Verwenden Sie ein Werkzeug zur Rauschunterdrückung
Die Rauschunterdrückung ist Ihre erste Verteidigungslinie gegen schlechte Audioqualität.
🛠 Empfohlene Werkzeuge:

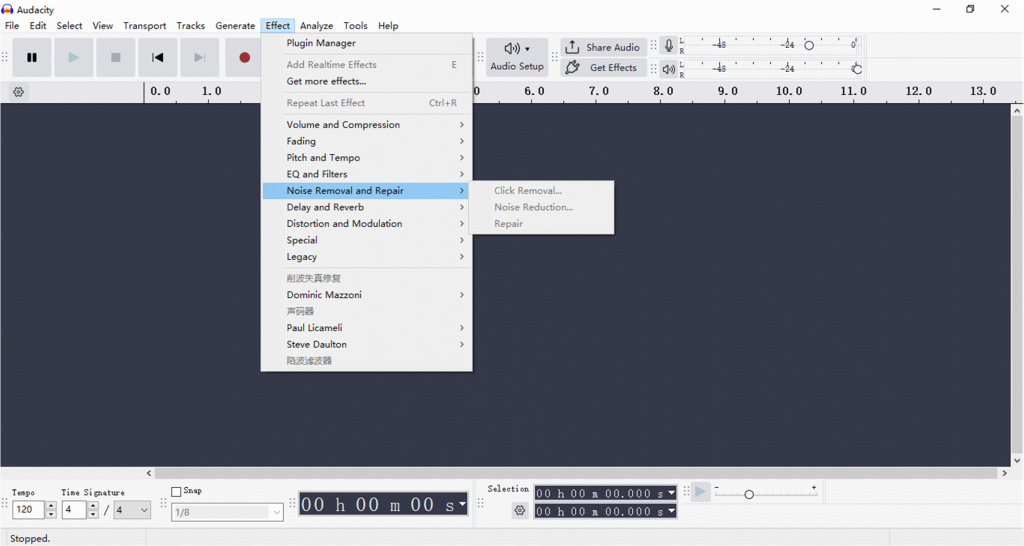
- Audacity (kostenlos): Audacity ist ein kostenloser Open-Source-Audio-Editor für die Aufnahme, Bearbeitung und Bereinigung von Ton. Ich empfehle ihn sehr.
- Importieren Sie Ihr Audio.
- Wählen Sie ein Segment aus, das nur Hintergrundgeräusche enthält.
- Gehe zu Effekt > Rauschunterdrückung > Rauschprofil abrufen.
- Wählen Sie dann das gesamte Audiomaterial aus und wenden Sie die Rauschunterdrückung an.
- Adobe Audition (Bezahlt):
- Verwenden Sie Rauschunterdrückung (Prozess) oder Adaptive Rauschunterdrückung unter dem Effekte-Bedienfeld für eine präzise Steuerung.
- Krisp / NVIDIA RTX Stimme (Real-Time):
- Diese Tools entfernen Hintergrundgeräusche bei Live-Aufnahmen oder Anrufen und helfen so, Probleme an der Quelle zu reduzieren.
Tipp: Hören Sie sich Ihr gesäubertes Audiomaterial immer an, um sicherzustellen, dass es nicht "roboterhaft" oder überbearbeitet klingt.
✂️ 2. Stille und unnötige Geräusche abschneiden
Lange Pausen, Füllgeräusche und irrelevantes Geschwätz verwirren die Transkriptionswerkzeuge und verschwenden Zeit.
Was zu entfernen ist:
- Lange Stille
- Husten, Niesen
- Hintergrundgespräch
- Echoartige Hallfahnen
Sie können verwenden Audacity, Ocenaudiooder andere einfache Editoren, um diese manuell oder mit Stille-Erkennungsfunktionen zu schneiden.
🎚️ 3. Normalisieren und Ausbalancieren von Audiopegeln
Wenn ein Sprecher zu laut und ein anderer zu leise ist, kann AI Wörter verpassen oder Sprecher verwirren. Die Normalisierung trägt dazu bei, dass die Lautstärke in der gesamten Aufnahme gleich bleibt.
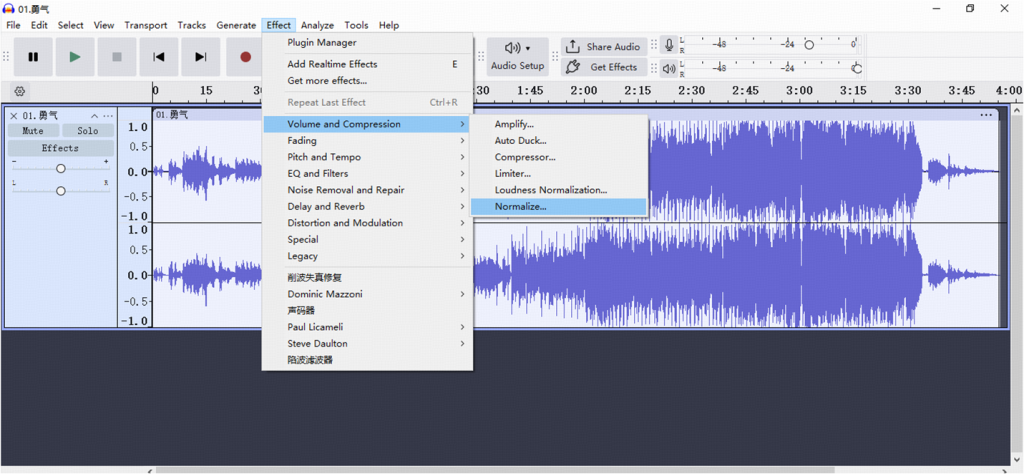
Wie man in Audacity normalisiert:
- Wählen Sie den kompletten Titel aus.
- Gehe zu Effekt > Normalisieren.
- Wählen Sie die Standardeinstellungen oder stellen Sie den Spitzenpegel auf -1,0 dB ein.
Dadurch wird Ihr Ton flüssiger und kann von der Transkriptionssoftware leichter verarbeitet werden.
🔁 4. In ein kompatibles Format konvertieren
Einige Transkriptionsanwendungen haben Probleme mit bestimmten Audioformaten (wie M4A). Um Probleme zu vermeiden, konvertieren Sie Ihr Audio in ein weithin unterstütztes Format.
Empfohlene Formate:
| Format | Qualität | Größe der Datei | Empfehlung |
|---|---|---|---|
| WAV | Beste (verlustfrei) | Groß | Ideal für maximale Genauigkeit bei der Transkription |
| MP3 | Gut (komprimiert) | Klein | Verwenden Sie eine hohe Bitrate (256kbps oder 320kbps) |
Werkzeuge zum Konvertieren:
Ich biete ein Online-Tool und ein Tool, das installiert werden muss, um unterschiedliche Bedürfnisse zu erfüllen.
- Online-Audio-Konverter
- FFmpeg (fortgeschrittene Benutzer)
👥 5. Separate Lautsprecher (wenn möglich)
Transkriptionstools, die Sprecherbeschriftungen unterstützen, funktionieren besser, wenn das Audiomaterial sauber und eindeutig pro Sprecher ist.
Wenn Sie Mehrkanal-Aufnahmegeräte verwenden oder Interviews führen, trennen Sie die Tonspuren der Sprecher vor dem Hochladen.
Werkzeuge für die Bearbeitung mit mehreren Sprechern:
| Werkzeug | Stärken | Schwachstellen | Am besten für |
|---|---|---|---|
| Beschreibung | - Automatische Transkription mit Sprechererkennung - Visuelle textbasierte Bearbeitung - Moderne Benutzeroberfläche, einsteigerfreundlich | - Eingeschränkte Audiokontrolle - Kostenlose Version mit eingeschränkten Funktionen | Podcaster, Autoren von Inhalten, Interviews |
| Audio-Hijacking | - Multitrack-Aufnahme in Echtzeit - Routing und Aufnahme von mehreren Anwendungen/Geräten - Erweiterte Audio-Pipeline-Steuerung | - nur macOS - Schwache Nachbearbeitungsmöglichkeiten | Interviews mit mehreren Personen, Live-Aufnahmen |
| iZotope RX | - Industrietaugliche Rauschunterdrückung und -reparatur - Hervorragend geeignet für Stimmentrennung und Rauschunterdrückung - Mit Plug-ins in hohem Maße anpassbar | - Steile Lernkurve - Teuer, für Profis gedacht | Tontechniker, Film-/Rundfunkredakteure |
Wenn eine Trennung der Sprecher nicht möglich ist, vermeiden Sie einfach, dass sich die Leute während der Aufnahme gegenseitig übersprechen.
✅ Bonustipps für besseren Klang (noch vor der Aufnahme)
- Verwenden Sie eine externes Mikrofonund nicht das Mikrofon Ihres Laptops oder Telefons.
- Nehmen Sie in einem ruhigen Raum mit weichen Möbeln auf, um das Echo zu reduzieren.
- Machen Sie eine kurze Testaufnahme und hören Sie auf Hintergrundgeräusche.
- Stummschalten von Benachrichtigungen oder Computerlüftern während der Sitzung.
Abschließende Überlegungen
Die Reinigung von verrauschten Audiodaten mag wie ein zusätzlicher Schritt erscheinen, aber sie kann Stunden der Bearbeitung und Korrektur später. Ganz gleich, ob Sie Otter, VOMO, Notta oder ein anderes Tool verwenden - wenn Sie der KI saubere Eingaben geben, erhalten Sie auch saubere Ergebnisse.
Wenn Sie also das nächste Mal eine Sprachaufnahme für die Transkription vorbereiten...erst reinigen, dann abschreiben.
Sie möchten wissen, welche Transkriptionstool funktioniert am besten bei verrauschtem Audio? Lesen Sie hier unsere vollständigen Bewertungen.
